







Бесплатная программа для распознавания текста gImageReader
Системы оптического распознавания текстов (Optical Character Recognition, OCR) профессионального уровня нельзя отнести к категории бюджетных программных решений — таковы современные реалии: за всё в этой жизни приходиться платить, особенно если дело касается цифровых технологий и интеллектуальной собственности. К примеру, стоимость признанного во всём мире продукта данного класса ABBYY FineReader PDF 15 версии Standard для домашнего использования составляет от 4 тысяч рублей в зависимости от типа приобретаемой лицензии, а корпоративные редакции и вовсе стартуют с внушительной отметки в 49 тысяч рублей за одну копию «Файнридера». Тут уж поневоле задумаешься об альтернативных вариантах приложений для автоматизированного перевода изображений рукописного, машинописного или печатного текста в текстовые данные.
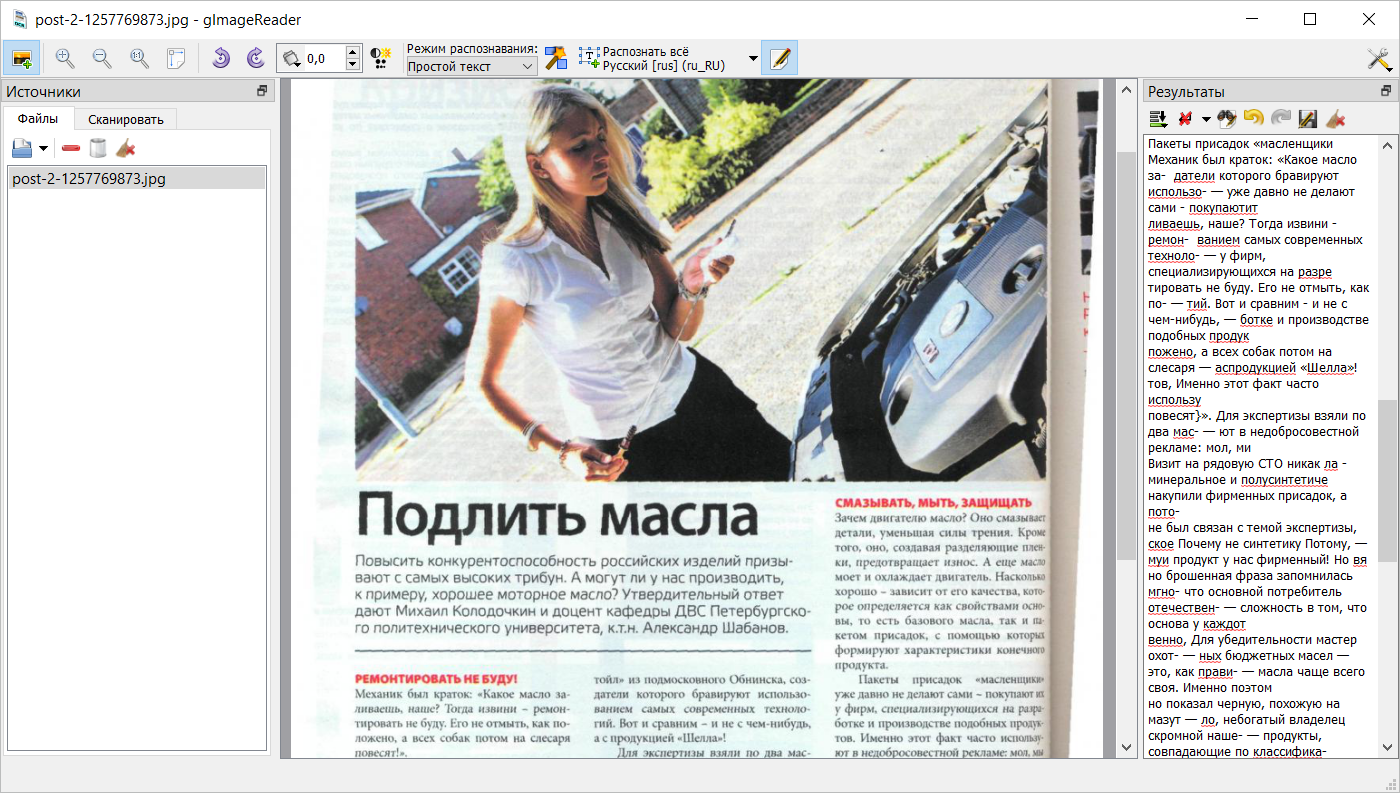
К числу таких решений относится бесплатная программа gImageReader, созданная на базе свободно распространяемого OCR-движка Tesseract, к созданию которого в своё время приложили силы эксперты Hewlett-Packard, одной из крупнейших американских компаний в сфере информационных технологий.
Приложение gImageReader поддерживает работу с графическими и PDF-файлами, умеет распознавать тексты на многих языках (включая русский) и проверять орфографию, взаимодействует напрямую с подключёнными к компьютеру сканерами и может производить обработку документов в различных режимах. Стоит признаться, что свою работу программа выполняет на «троечку» с минусом и по сравнению с FineReader не обучено восстанавливать стили и форматирование исходного документа. Иными словами, вариант не из лучших, но всё же подходящий для случаев, когда необходимо на скорую руку, за бесплатно и в больших объёмах обработать множество PDF-файлов и бумажных документов.